







ZLG深度解析:语音识别技术
语音识别已成为人与机器通过自然语言交互重要方式之一,本文将从语音识别的原理以及语音识别算法的角度出发为大家介绍语音识别的方案及详细设计过程。
语言作为人类的一种基本交流方式,在数千年历史中得到持续传承。近年来,语音识别技术的不断成熟,已广泛应用于我们的生活当中。语音识别技术是如何让机器“听懂”人类语言?本文将为大家从语音前端处理、基于统计学语音识别和基于深度学习语音识别等方面阐述语音识别的原理。
随着计算机技术的飞速发展,人们对机器的依赖已经达到一个极高的程度。语音识别技术使得人与机器通过自然语言交互成为可能。最常见的情形是通过语音控制房间灯光、空调温度和电视的相关操作等。并且,移动互联网、智能家居、汽车、医疗和教育等领域的应用带动智能语音产业规模持续快速增长,2018年全球智能语音市场规模将达到141.1亿美元。

(数据来源:中商产业研究院整理)
目前,在全球智能语音市场占比情况中,各巨头市场占有率由大到小依次为:Nuance、谷歌、苹果、微软和科大讯飞等。
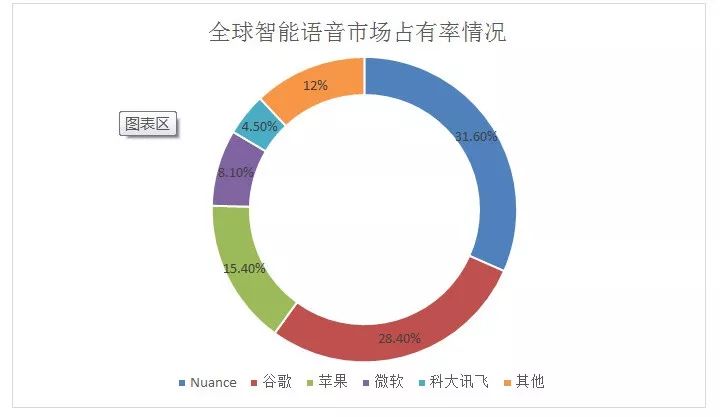
(数据来源:中商产业研究院整理)
语音识别的本质就是将语音序列转换为文本序列,其常用的系统框架如下:
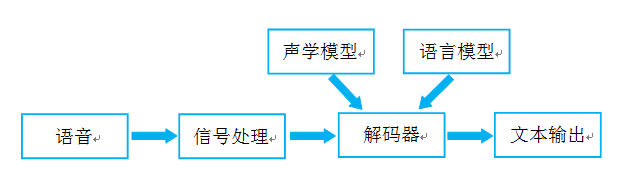
接下来对语音识别相关技术进行介绍,为了便于整体理解,首先,介绍语音前端信号处理的相关技术,然后,解释语音识别基本原理,并展开到声学模型和语言模型的叙述,最后,展示我司当前研发的离线语音识别demo。
1前端信号处理
前端的信号处理是对原始语音信号进行的相关处理,使得处理后的信号更能代表语音的本质特征,相关技术点如下表所述:
1、语音活动检测
语音活动检测(Voice Activity Detection, VAD)用于检测出语音信号的起始位置,分离出语音段和非语音(静音或噪声)段。VAD算法大致分为三类:基于阈值的VAD、基于分类器的VAD和基于模型的VAD。
基于阈值的VAD是通过提取时域(短时能量、短时过零率等)或频域(MFCC、谱熵等)特征,通过合理的设置门限,达到区分语音和非语音的目的;
基于分类的VAD是将语音活动检测作为(语音和非语音)二分类,可以通过机器学习的方法训练分类器,达到语音活动检测的目的;
基于模型的VAD是构建一套完整的语音识别模型用于区分语音段和非语音段,考虑到实时性的要求,并未得到实际的应用。
2、降噪
在生活环境中通常会存在例如空调、风扇等各种噪声,降噪算法目的在于降低环境中存在的噪声,提高信噪比,进一步提升识别效果。
常用降噪算法包括自适应LMS和维纳滤波等。
3、回声消除
回声存在于双工模式时,麦克风收集到扬声器的信号,比如在设备播放音乐时,需要用语音控制该设备的场景。
回声消除通常使用自适应滤波器实现的,即设计一个参数可调的滤波器,通过自适应算法(LMS、NLMS等)调整滤波器参数,模拟回声产生的信道环境,进而估计回声信号进行消除。
4、混响消除
语音信号在室内经过多次反射之后,被麦克风采集,得到的混响信号容易产生掩蔽效应,会导致识别率急剧恶化,需要在前端处理。
混响消除方法主要包括:基于逆滤波方法、基于波束形成方法和基于深度学习方法等。
5、声源定位
麦克风阵列已经广泛应用于语音识别领域,声源定位是阵列信号处理的主要任务之一,使用麦克风阵列确定说话人位置,为识别阶段的波束形成处理做准备。
声源定位常用算法包括:基于高分辨率谱估计算法(如MUSIC算法),基于声达时间差(TDOA)算法,基于波束形成的最小方差无失真响应(MVDR)算法等。

 分享
分享
图片新闻








技术文库
最新活动更多
-
1月8日火热报名中>> Allegro助力汽车电气化和底盘解决方案优化在线研讨会
-
1月9日立即预约>>> 【直播】ADI电能计量方案:新一代直流表、EV充电器和S级电能表
-
即日-1.16立即报名>>> 【在线会议】ImSym 开启全流程成像仿真时代
-
即日-1.20限时下载>>> 爱德克(IDEC)设备及工业现场安全解决方案
-
即日-1.24立即参与>>> 【限时免费】安森美:Treo 平台带来出色的精密模拟
-
即日-1.31立即参与>>> 【限时免费下载】村田白皮书
推荐专题







发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论