







4日10日 OFweek 2025(第十四届)中国机器人产业大会
立即报名 >>>
7.30-8.1 全数会2025(第六届)机器人及智能工厂展
火热报名中>>
ZLG深度解析:语音识别技术
6、波束形成
波束形成是指将一定几何结构排列的麦克风阵列的各个麦克风输出信号,经过处理(如加权、时延、求和等)形成空间指向性的方法,可用于声源定位和混响消除等。
波束形成主要分为:固定波束形成、自适应波束形成和后置滤波波束形成等。
2语音识别的基本原理
已知一段语音信号,处理成声学特征向量之后表示为,其中表示一帧数据的特征向量,将可能的文本序列表示为,其中表示一个词。语音识别的基本出发点就是求,即求出使最大化的文本序列。将通过贝叶斯公式表示为:
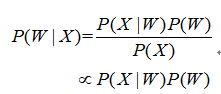
其中,称之为声学模型,称之为语言模型。大多数的研究将声学模型和语言模型分开处理,并且,不同厂家的语音识别系统主要体现在声学模型的差异性上面。此外,基于大数据和深度学习的端到端(End-to-End)方法也在不断发展,它直接计算 ,即将声学模型和语言模型作为整体处理。本文主要对前者进行介绍。
3声学模型
声学模型是将语音信号的观测特征与句子的语音建模单元联系起来,即计算。我们通常使用隐马尔科夫模型(Hidden Markov Model,HMM)解决语音与文本的不定长关系,比如下图的隐马尔科夫模型中。
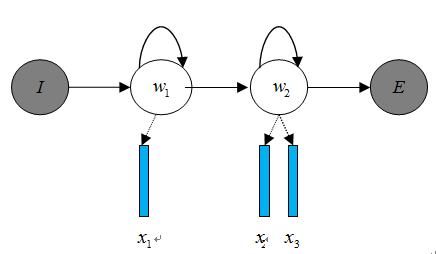
将声学模型表示为
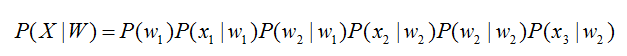
其中,初始状态概率和状态转移概率( 、 )可用通过常规统计的方法计算得出,发射概率( 、 、 )可以通过混合高斯模型GMM或深度神经网络DNN求解。
传统的语音识别系统普遍采用基于GMM-HMM的声学模型,示意图如下:

其中,表示状态转移概率,语音特征表示,通过混合高斯模型GMM建立特征与状态之间的联系,从而得到发射概率,并且,不同的状态对应的混合高斯模型参数不同。
基于GMM-HMM的语音识别只能学习到语音的浅层特征,不能获取到数据特征间的高阶相关性,DNN-HMM利用DNN较强的学习能力,能够提升识别性能,其声学模型示意图如下:
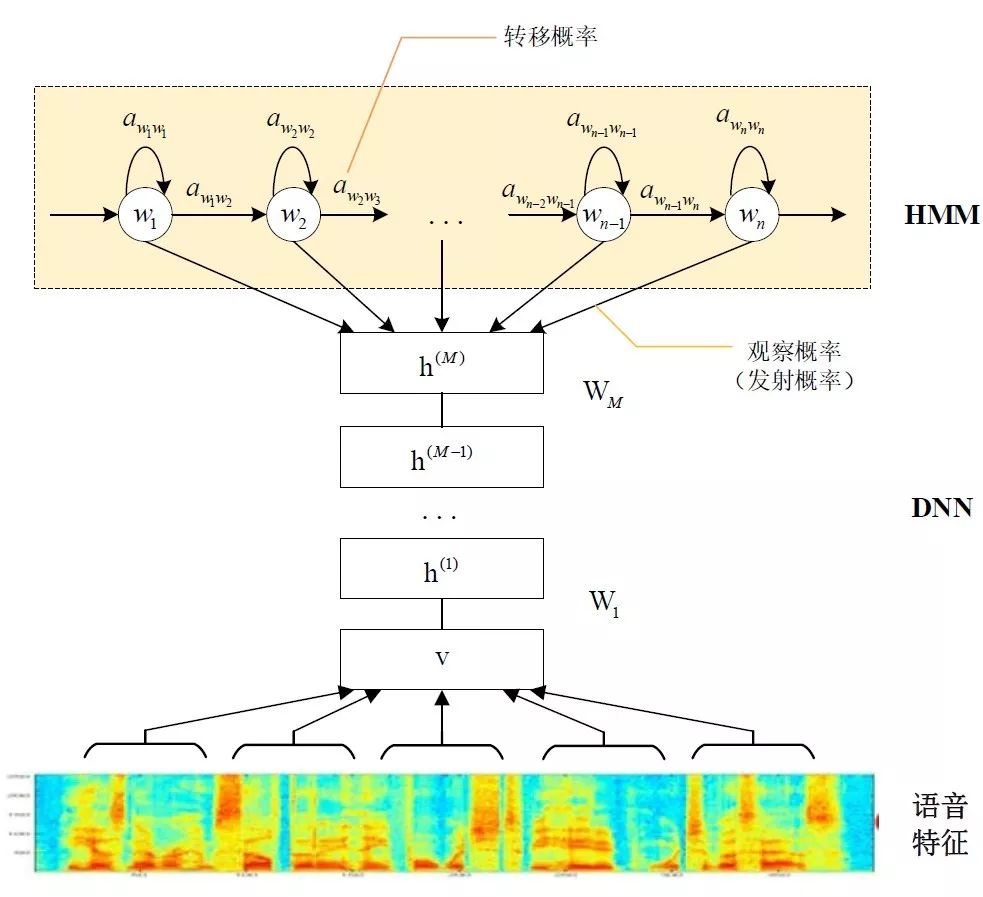
GMM-HMM和DNN-HMM的区别在于用DNN替换GMM来求解发射概率,GMM-HMM模型优势在于计算量较小且效果不俗。DNN-HMM模型提升了识别率,但对于硬件的计算能力要求较高。因此,模型的选择可以结合实际的应用调整。
4语言模型
语言模型与文本处理相关,比如我们使用的智能输入法,当我们输入“nihao”,输入法候选词会出现“你好”而不是“尼毫”,候选词的排列参照语言模型得分的高低顺序。
语音识别中的语言模型也用于处理文字序列,它是结合声学模型的输出,给出概率最大的文字序列作为语音识别结果。由于语言模型是表示某一文字序列发生的概率,一般采用链式法则表示,如是由组成,则可由条件概率相关公式表示为:

由于条件太长,使得概率的估计变得困难,常见的做法是认为每个词的概率分布只依赖于前几个出现的词语,这样的语言模型成为n-gram模型。在n-gram模型中,每个词的概率分布只依赖于前面n-1个词。例如在trigram(n取值为3)模型,可将上式化简:

5语音识别效果展示
基于PC的语音识别展示demo如下视频所示:
视频包括使用“小致同学”唤醒设备,设备唤醒之后有12秒时间进行语音识别控制,空闲时间超过了12秒将再次休眠。
我们的语音识别算法已经部分移植到了基于AWorks的cortex-m7系列M1052-M16F12 8AWI -T平台。语音识别的声学模型和语言模型是我司训练的用于测试智能家居控制的相关模型demo,在支持65个常用命令词的离线识别测试中(数量越大识别所需时间越长),使用读取本地音频文件的方式进行语音识别“打开空调”所需时间0.46s左右。下面是在M1052-M16F128AWI-T的实测效果:

6关于算法库获取
目前语音识别系统处于研发阶段,广大客户可将自身需求反馈给周立功单片机有限公司与致远电子有限公司相关市场人员,我们会以最快速度研发客户需要的产品。

M1052-M16F128AWI-T产品图片

 分享
分享

图片新闻








最新活动更多
-
即日-3.21立即报名 >> 【深圳 IEAE】2025 消费新场景创新与实践论坛
-
即日-3.25立即报名 >>> 【在线会议】医疗设备的无线共存、高速数字与射频测试
-
3月27日立即报名>> 【工程师系列】汽车电子技术在线大会
-
即日-3.31立即报名>>> 【在线会议】AI加速卡中村田元器件产品的技术创新探讨
-
4月1日立即下载>> 【村田汽车】汽车E/E架构革新中,新智能座舱挑战的解决方案
-
4日10日立即报名>> OFweek 2025(第十四届)中国机器人产业大会
推荐专题




-
10 英伟达,我命由天不由我







发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论