







4日10日 OFweek 2025(第十四届)中国机器人产业大会
立即报名 >>>
7.30-8.1 全数会2025(第六届)机器人及智能工厂展
火热报名中>>
英特尔架构炼金术:持续拓宽摩尔定律边界
文︱郭紫文
图︱英特尔
如今,科技已经处于世界的中心,人们的生活与数字技术交织交融。在计算机视觉、加密数字货币、去中心化金融、增强现实(AR)、元宇宙等技术的飞速发展下,对于CPU、GPU、FPGA等工作负载处理能力的要求也逐渐提升。正如英特尔公司高级副总裁兼加速计算系统和图形事业部总经理Raja Koduri所说,强大的计算能力至关重要。
早在2018年,英特尔便提出以制程、架构、存储、互联、安全、软件为六大战略支柱,并明确了计算新时代必要的四大基础计算架构,即标量、矢量、矩阵和空间架构。2021年,帕特·基辛格担任英特尔CEO一职,并宣布了全新的制造战略IDM2.0,随后英特尔公布了其有史以来最详细的路线图,涉及晶体管、互连、封装等技术,持续拓展摩尔定律边界。
Raja表示,无论是高需求工作负载,还是追求创新的客户,都有一个共同的元性能要求。“为了在2025年满足1000x(千倍级)处理能力提升的需求,我们要在每个技术领域,实现至少4倍左右的摩尔定律提升,这些领域包括制程工艺、封装、内存和互连,而架构是将它们与软件结合起来的‘炼金术’。”
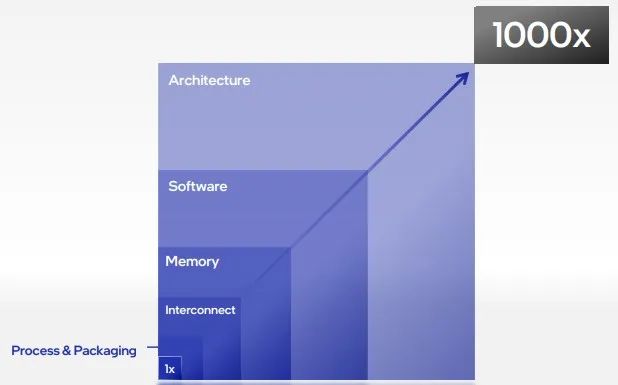
工作负载千倍级提升需求
在2021年英特尔架构日上,Raja携手英特尔多位架构师,面向CPU、GPU和IPU,发布了英特尔重大技术架构的创新,全面揭露了英特尔路线图新产品背后的架构细节。

2021英特尔架构日架构创新
首个性能混合架构:能效与性能全面提升
自1978年x86架构诞生开始,英特尔持续完善x86架构生态,拓展其在计算机、服务器等高性能高功耗领域的市场。在本次架构日上,英特尔发布了全新一代的x86内核微架构,包括能效核微架构与性能核微架构,以及首个性能混合架构Alder Lake。
“英特尔的首要目标是,打造世界上极高能效的x86 CPU内核。”能效核微架构(E-Core)此前代号为“Gracemont”,英特尔利用intel 7 优化设计,提升面积效率,进而扩展产品内核数量,最大限度降低能耗,提高CPU能效比。
我们知道,Skylake是英特尔迄今为止最多产的CPU微架构。与之相比,能效核架构在相同功耗下单线程性能提升40%;相同性能时,功耗比Skylake低40%。其次,在吞吐量方面,与运行四个线程的两个Skylake内核相比,四个能效核在性能提升80%的同时功耗更低,或者在提供相同吞吐量性能时,功耗降低80%。英特尔x86能效核的首席架构师Stephen Robinson介绍,高度可扩展的x86能效核架构,应用范围覆盖了从低功耗移动应用到多核微服务等领域。


能效核性能提升
x86性能核架构(P-Core)专为速度设计,突破了低时延、单线程应用性能限制。据英特尔性能核首席架构师Adi Yoaz介绍,性能核架构前身为“Golden Cove”,专注于实现CPU架构性能提升,不断完善AVX矢量加速硬件、指令集架构(ISA)性能,为低TDP笔记本电脑、台式机、数据中心提供全面的支持。此外,该架构以“更宽、更深、更智能”的特性,提高了指令执行的并行性及通用性能。在频率相同的情况下,与Cypress Cove内核架构相比,性能核架构对大范围工作负载实现了19%的处理能力提升。
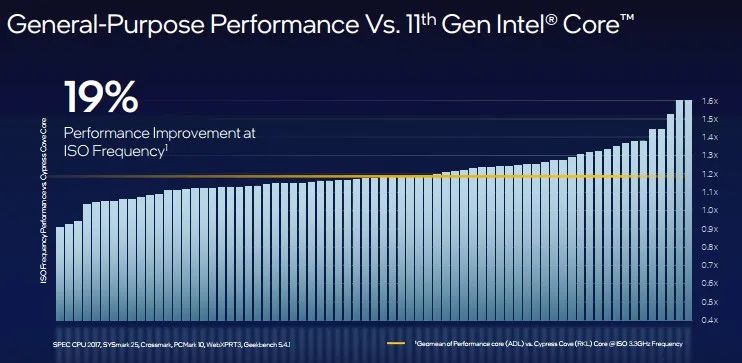
性能核性能提升
将上述能效核与性能核的优势相结合,英特尔在一个系统中实现了两者的最佳结合,兼具高可扩展性、多线程、低时延特性。通过硬件线程调度器,英特尔将能效核与性能核无缝衔接,协同运行,最大限度提升系统的能效与性能。这就是英特尔首个性能混合内核架构Alder Lake,据英特尔Alder Lake首席架构师Arik Gihon透露,基于该架构的产品也将在今年开始出货。
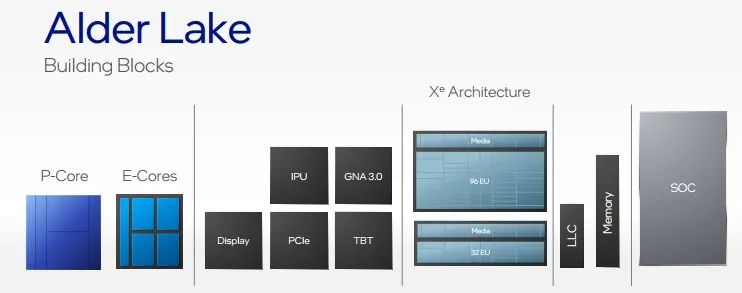
首个性能混合内核架构Alder Lake
“支持如此广泛的功率设计和性能是一项艰巨的芯片设计挑战,英特尔通过业界一流IP,实现了晶片级可配置,全面优化性能和效率。”Arik Gihon表示,英特尔Alder Lake基于intel 7制程,通过单一可扩展的SoC架构,支持所有客户端细分市场。
全新独立显卡架构,发烧友级别性能提升
较之集成显卡,独立显卡更能释放潜能。从第9代到Xe-LP,英特尔已经连续两年将显卡性能逐年翻倍。今年,英特尔依然关注显卡的性能和质量,专注于构建内核驱动程序本身的设计,并推出了Xe HPG独立显卡微架构,为游戏和创作工作负载提供了发烧级的高性能水准。对游戏玩家来说,英特尔独立显卡结合所有视觉元素,生成了近乎真实的视觉效果。
从引擎核心到逻辑设计,Xe HPG微架构进行了全面的升级和优化,完成了代码重构,独立显卡本地内存利用率也得到优化,支持硬件光线追踪、网格着色和采样器反馈。为满足高质量渲染,英特尔研发了易于集成的XeSS API,通过深度学习来提升渲染分辨率和质量。与Xe-LP的 Iris Xe Max 产品IP相比,Xe HPG将相对运行频率和每瓦性能分别提高约1.5倍。
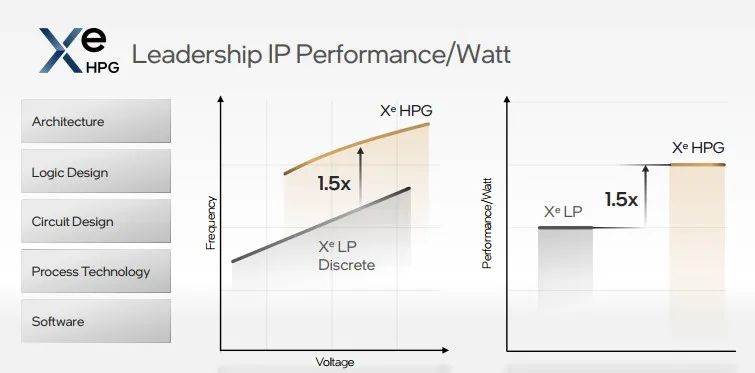
Xe HPG性能提升
针对Xe HPG微架构,英特尔还打造了Xe内核,包括16个矢量引擎和16个矩阵引擎(XMX)。其中,矩阵引擎能够加速AI工作负载,实现高性能、高保真的游戏体验,是英特尔Xe HPG实现高效计算的关键。
基于Xe HPG架构,英特尔推出Alchemist系列SoC,拥有出色的可扩展性和计算效率。据悉,该产品将于2022年第一季度上市,并采用英特尔锐炫(Intel ArcTM)作为新的品牌名。
数据中心架构新标准
面向数据中心领域,英特尔在技术模块上的研发投入长达数年。本次架构日上,英特尔着重介绍了下一代至强可扩展处理器Sapphire Rapids、基础设施处理器(IPU)Mount Evans,以及面向百亿亿次计算的GPU Ponte Vecchio。
“我们正处于一场基础建设革命中,计算本身与如何提供计算同样重要。英特尔不仅提供从边缘到云的计算能力,同时也为用户提供建设数据中心的方案。”近期,在Six Five峰会上,英特尔发布了IPU基础设施处理器,将基础设施与用户工作负载隔离,让用户更好地管控CPU,也为基础设施功能减负,提升架构灵活性和吞吐量。
在提升计算能力方面,英特尔首席数据中心架构师Sailesh表示,Sapphire Rapids将为数据中心架构树立新的标准,对计算性能和并行工作负载进行优化和提升。该处理器以模块化分区架构为核心,采用英特尔嵌入式多芯片互连桥接(EMIB)封装技术,能够保持单晶片接口优势,拥有高可扩展性、低时延和高横向带宽等优点。
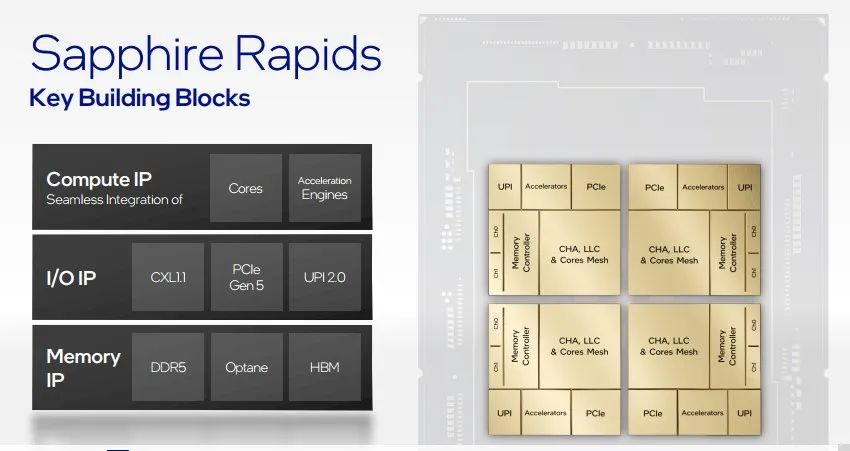
Sapphire Rapids
英特尔另一项为数据中心提升计算能力的方案基于Xe HPC微架构的Ponte Vecchio芯片。英特尔Ponte Vecchio首席架构师Masooma Bhaiwala表示,该芯片是英特尔历来最复杂的芯片,更像是包含诸多芯片的集合。英特尔将计算单元、Rambo单元、Xe链路单元以及包含高速HBM内存的基础单元通过高带宽互连进行组装,实现单元之间低功耗高速连接。

Ponte Vecchio
在吞吐量计算密度与对高带宽内存的支持方面,英特尔连续十年都处于落后地位。作为英特尔缩小差距的杀手锏,Ponte Vecchio芯片在每秒浮点运算次数和计算密度上已经具有业界领先优势。
总结
在2021英特尔架构日上,英特尔CEO 帕特·基辛格表示:“我们的战略和执行都在加速,我们正为英特尔创新与技术领先的新时代描绘蓝图。英特尔在软件、芯片和平台方面的深度与广度,在封装和制程工艺方面的技术,以及在大规模制造上的实力,赋予英特尔独特的位势,去抓住这一巨大的增长机遇。”
面向CPU、GPU、IPU等多个方向,从边缘和终端设备到网络、再到云,英特尔专注研发最优架构及平台创新,以迎接日益艰巨的高性能计算挑战。

 分享
分享

图片新闻








技术文库
最新活动更多
-
即日-3.27立即报名>> 【在线直播】解密行业检测流量密码——电子与半导体行业
-
3月27日立即报名>> 【工程师系列】汽车电子技术在线大会
-
即日-3.28立即报名>>> 【在线会议】汽车检测的最佳选择看这里
-
即日-3.31立即报名>>> 【在线会议】AI加速卡中村田元器件产品的技术创新探讨
-
4月1日立即下载>> 【村田汽车】汽车E/E架构革新中,新智能座舱挑战的解决方案
-
4日10日立即报名>> OFweek 2025(第十四届)中国机器人产业大会
推荐专题











发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论